
Hello everyone! New Year, New Life, and finally, old dreams and goals are coming out of the paper. For my first blog, at the beginning of 2022, I chose to talk about Oracle Database Kubernetes Operator, a.k.a OraOperator.
This article also offers a gentle introduction to Kubernetes Operator, and I could not leave out the Cloud Native Architecture – base for all.
Gentle introduction to Kubernetes Operator
Why write a Kubernetes operator? What is an Operator, and why is it vital to the specialized system to run over Kubernetes in symbiosis? I will try to explain in this gentle introduction to Operator.
The Cloud Native Design Principles
First, as a baseline, a Cloud Native Architecture is a set of principles or practices focused on optimizing systems for the unique resources of the Cloud, seeking to achieve increased agility and maintainability of applications, resilience, scalability and efficient consumption of resources, to list some of the main goals. We can summarize these principles through the scheme presented in the figure below.
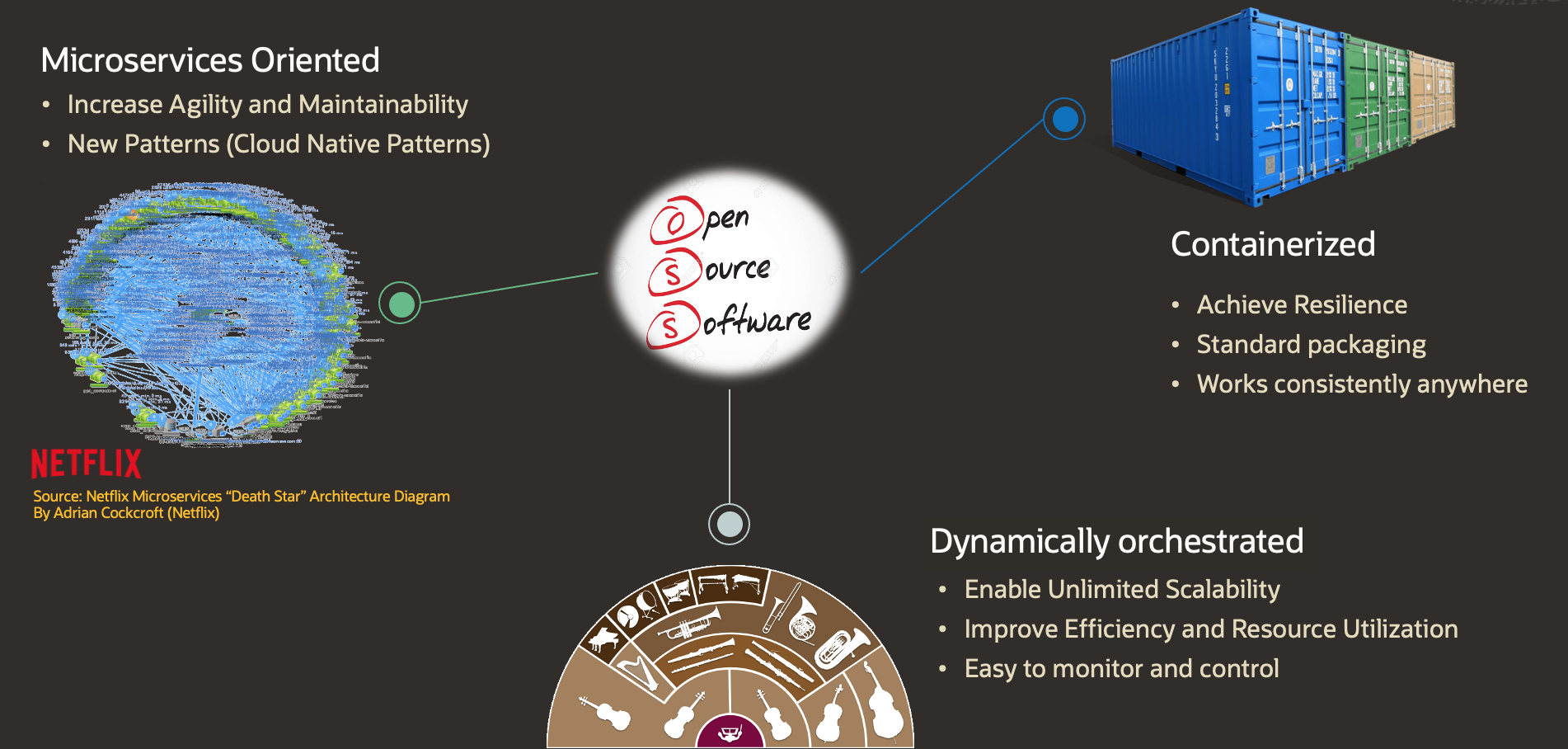
These design principles suggest the adoption of a microservices architecture, dividing applications with a focus on increasing their agility and maintainability.
Using containers to package and distribute the microservices provides an immutable infrastructure seeking to achieve application resilience; And dynamically orchestrates these containers with a focus on efficient consumption of resources while enabling elasticity.
The Kubernetes project is the engine in charge of dynamically orchestrating the containers, leveraging the capabilities of the containers managing their whole lifecycle, and providing capabilities such as self-healing and reconciliation.
But containers are by best practices ephemerals, which means that if they die, there isn’t a state saved, or better, you lose everything inside it. This stateless approach follows the sixth factor from the 12-factor app methodology, which recommends “execute the app as one or more stateless processes.”.
And, also, Kubernetes was not projected to manage the state by default. Thus, how can we take advantage of containerizing and dynamic orchestrating coming from Kubernetes to run highly distributed data stores, like a Database? How can we “adapt” our stateful application to use Kubernetes and at the same time persist state, apply data replication, failover automation (again manage state), and so on?
Ok, it is possible to do it handmade, which means writing code to overpass the stateless environment and provide what we require, but to be honest, it is an error-prone and Herculius task. At this point, let Operador works for you.
The Kubernetes Operator
Using an idea very present these days, “Everything as a code,” an Operator Pattern is a way of putting the system operator, our well-known sysadmin or dba, “as a code.” The Operator has 3 components, a specialized or domain-oriented executor process – the Controller – which sits in the loop, watching an application or an infrastructure, to ensure that its states during execution – the current state – are the desired ones, and that is documented by the state declared in a domain-specific language.
Looking for Kubernetes, a most concise description from Jimmy Zelinskie is “An operator is a Kubernetes Controller that understands 2 domains: Kubernetes and something else. Combining both domains’ knowledge can automate tasks that usually require a human operator that understands both domains”.
Bellow diagram explains this observability state from the Operator to maintain the desired state based on comparing declared and current states.
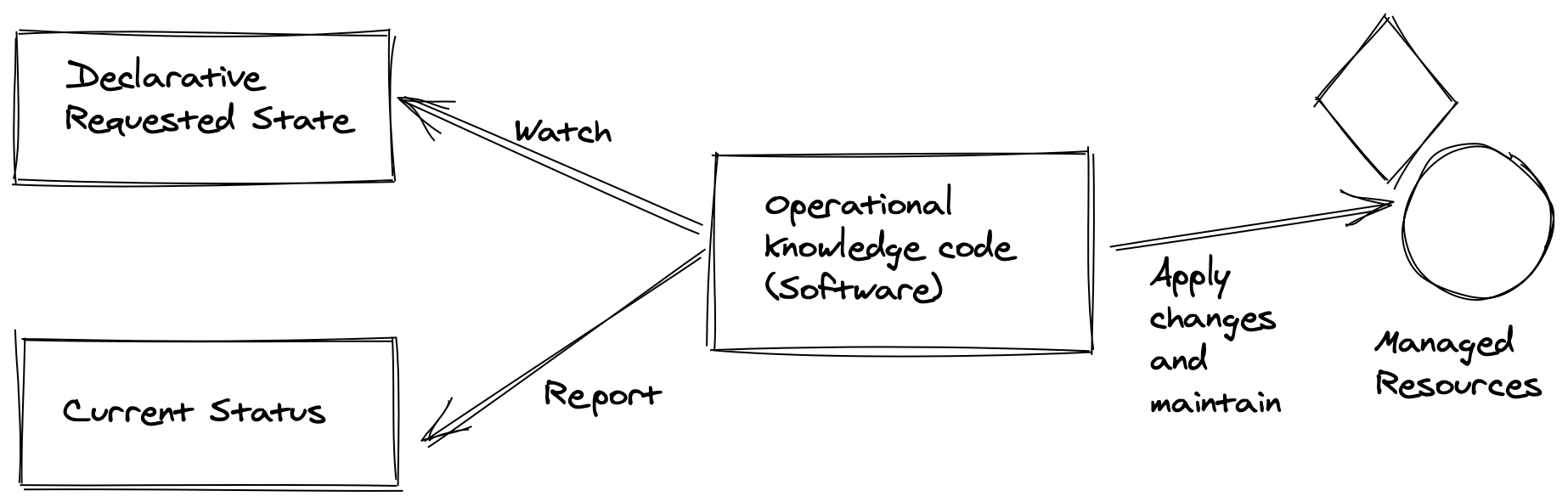
Thus when we have a stateful application or infrastructure to deploy and manage and decide to build an Operator, we create a Kubernetes Controller with the capabilities to understand and interact with Kubernetes Domain and its APIs. And, at the same time, to understand that specialized domain and operates to provide stateful management, failover automation without breaking the application consistency, also administrative functions like backup/restore, besides many other crucial operational tasks, all “as Code.”
In addition to the Controller, the Operator also includes Custom Resources and Custom Resource Definitions (CRDs). The desired state of the application is encapsulated in one or more CRDs using the domain-specific language, and the Controller has the operational knowledge lead with these definitions and gets the objects from the application to the desired state.
For further details about Kubernetes Operator, I recommend the CNCF Operator White Paper.
Oracle Database Operator for Kubernetes (a.k.a. OraOperator)
I am not afraid to say that Kubernetes is the infrastructure orchestrator of the Cloud, providing the dynamic mechanism to handle the Containers, providing resilience, self-healing, a kind of operational elasticity. And, running and taking advantage of this fantastic technology is key to success on Cloud Native deployments.
It is fantastic that Oracle has decided to make Oracle Database Kubernetes-native, which makes the most critical and adopted Database of the World operable and observable by an essential building block of Cloud Native infrastructure.
Oracle Database is a stateful infrastructure and requires enterprise-ready operational capabilities, like backup/restore, resilience, failover automation, etc. Thus, to make it viable to run over Kubernetes, Oracle released the Oracle Database Operator for Kubernetes [ OraOperator ], which follows Operator Pattern. Creating the integration between the infrastructure of the Kubernetes and the infrastructure of the Oracle Database, allowing them to work together to deliver one of the most powerful Cloud Native Data Management platforms.
The OraOperator project implemented Kubernetes resources like Controllers and Custom Resources Definitions for automating some tasks from Oracle Database lifecycle management. For example, the bellow code of the CRD for Sharding Database.
| |
OraOperator Support Configurations
The current release (v0.1.0) also supports off-Kubernetes-cluster management tasks, which helps the Database Reliable Engineers (DBRE) with their daily job throughout Kubernetes – kubectl – commands. This means that it is possible to operate Oracle Autonomous Database (ADB) using the OraOperator.
The bellow list summarizes which Oracle Database Configuration and their supported operations:
- off-K8s-cluster
- Database Configuration: Autonomous DB 1
- Operations:
provision, bind, start, stop, terminate (soft/hard), scale (down/up)
- Operations:
- Database Configuration: Autonomous DB 1
- in-K8s-cluster
- Database Configuration: Single Instance databases (SIDB) 2
- Operations:
provision, clone, patch (in-place/out-of-place), update database initialization parameters, update database configuration (Flashback, archiving), Oracle Enterprise Manager (EM) Express (a basic observability console)
- Operations:
- Database Configuration: Containerized Sharded databases (SHARDED)
- Operations:
provision/deploy sharded databases and the shard topology, add a new shard, delete an existing shard
- Operations:
- Database Configuration: Single Instance databases (SIDB) 2
A big picture of the Operator for Sharded Database
As a usage example, the below diagram shows the adoption of the OraOperator for deploying the Oracle Database Sharded option. After installing the Operator inside OKE 3, we will install our database sharded with two containers for sharded DBs instances, two containers with GMS, and one Catalog instance.
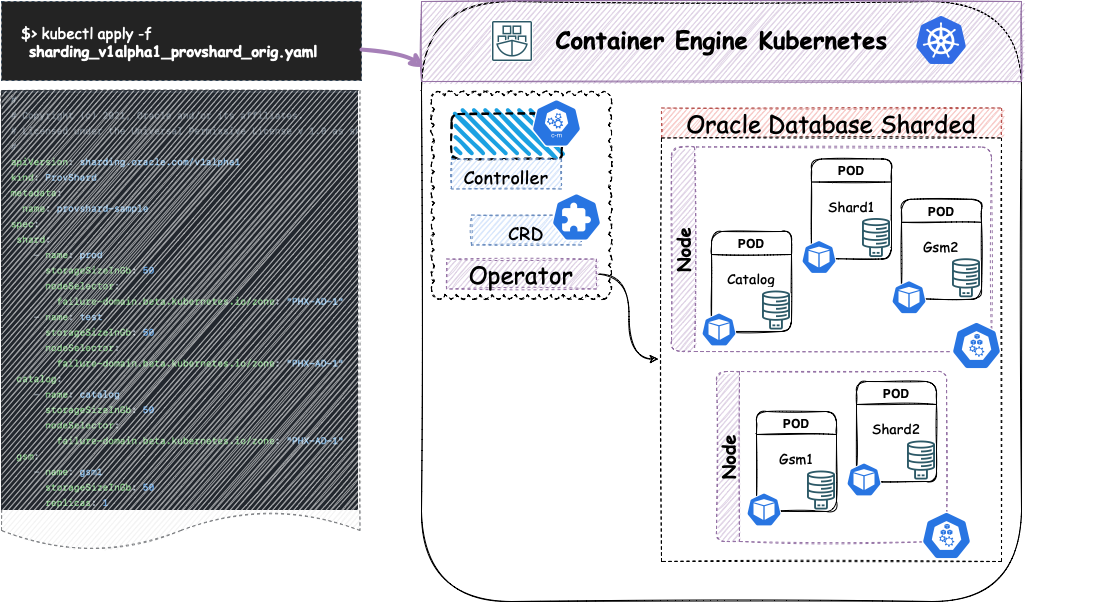
Release review
The release 0.1.0 comes with many valuable features for us developers and BDREs. For example, it works with the Oracle Database Single Instance (SIDB) and can be deployed on our laptop using Minikude. The next release will increase the number of Kubernetes distributions from other vendors that will be certified and database configuration options such as local databases (CDB/PDB).
Also, the current release of OraOperator (v0.1.0) must be for development and test only. DO NOT USE IT IN PRODUCTION.
References
Some references to continue study:
- Oracle Database Operator for Kubernetes GitHub
- Material from my friend and project leader Kuassi Mensah (Director of Product Management for Java access to Oracle DB)
What next?
Yes, this article is the pilot from a Serie about Oracle Database Operator for Kubernetes, and the next episode will be about “Getting started with OraOperator for Single Instance databases.”
Oracle Autonomous Database on shared Oracle Cloud Infrastructure (OCI), also known as ADB-S ↩︎
Containerized Single Instance databases (SIDB) ↩︎
Oracle Container Engine for Kubernetes (OKE) is an Oracle-managed Kubernetes service from Oracle Cloud Infrastructure. ↩︎