
Olá pessoal! Ano Novo, Vida Nova e, por fim, velhos sonhos e metas estão saindo do papel. Para o meu primeiro blog, no início de 2022, optei por falar sobre o Operador de Kubernetes do Banco de Dados Oracle, também conhecido como OraOperator.
Este artigo também oferece uma introdução bem resumida do Operador de Kubernetes, e eu não poderia deixar de fora a Arquitetura Nativa para Cloud – base para todos.
Simples introdução ao Operador de Kubernetes
Por que escrever um operador de Kubernetes? O que é um operador e por que é vital para o sistema especializado executar no Kubernetes, quase uma simbiose? Vou tentar explicar nesta introdução gentil ao Operator.
Os Princípios do Projeto Nativos para Cloud
Primeiro, como linha de base, uma Arquitetura Nativa para Cloud é um conjunto de princípios ou práticas focados na otimização de sistemas para os recursos exclusivos da Cloud, buscando atingir o aumento da agilidade e da manutenabilidade das aplicações, resiliência, escalabilidade e consumo eficiente de recursos, para listar alguns dos objetivos principais. Podemos sumarizar esses principios através do esquema apresentado na figura abaixo.
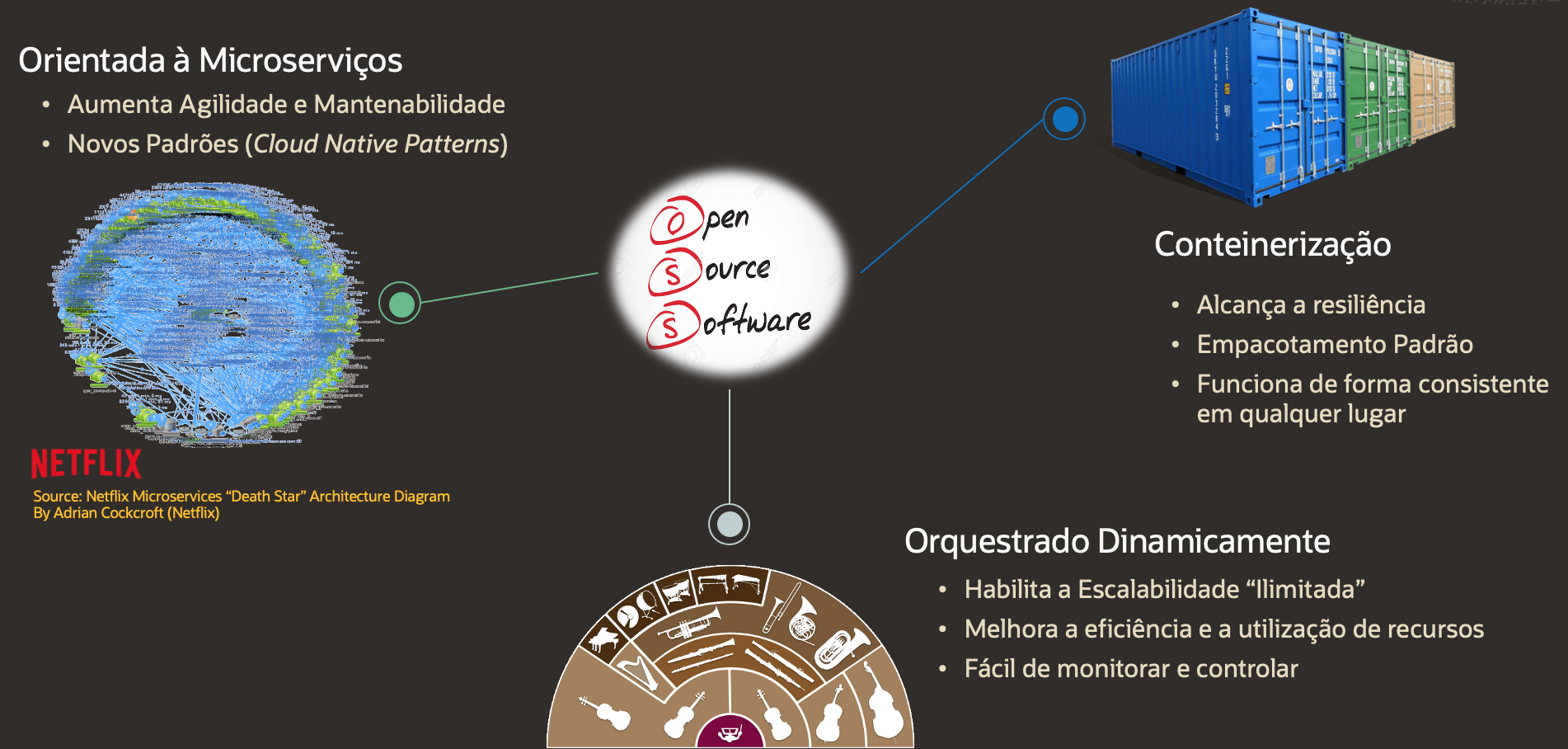
Esses princípios de projeto sugerem a adoção de uma arquitetura de microsserviços, dividindo as aplicações com foco em aumentar sua agilidade e manutenibilidade.
O uso de contêineres para empacotar e distribuir os microsserviços fornece uma infraestrutura imutável buscando alcançar a resiliência do aplicativo; E orquestra dinamicamente esses contêineres com foco no consumo eficiente de recursos, ao mesmo tempo em que permite a elasticidade.
O projeto Kubernetes é de fato o mecanismo responsável por orquestrar dinamicamente os contêineres, aproveitando os recursos deles e gerenciando todo o seu ciclo de vida, e também fornecendo recursos como autorrecuperação e reconciliação.
Mas os contêineres são efêmeros, por melhores práticas, o que significa que, se eles morrerem, não haverá um estado salvo, ou melhor, você perde tudo dentro dele. Essa abordagem sem estado segue o sexto fator da metodologia de aplicativo de 12 fatores, que recomenda “executar o aplicativo como um ou mais processos sem estado”.
E, também, o Kubernetes não foi projetado para gerenciar o estado por padrão. Assim, como podemos aproveitar a conteinerização e a orquestração dinâmica provenientes do Kubernetes para executar armazenamentos de dados altamente distribuídos, como um banco de dados? Como podemos “adaptar” nosso aplicativo com estado para usar o Kubernetes e ao mesmo tempo persistir o estado, aplicar replicação de dados, automação de recuperação a falhas (novamente gerenciar estado) e assim por diante?
Ok, é possível fazer “na mão”, o que significa escrever código para sobrepor o ambiente sem estado e fornecer o que precisamos, mas para ser honesto, é uma tarefa propensa a erros e Hercúlea. É aí que você deixa o Operador trabalhar para você.
O Operador de Kubernetes
Usando uma ideia bastante presente nos dias de hoje, “Tudo como um código”, um Padrão Operador é uma maneira de colocar o sujeito operador de sistemas, nosso conhecido sysadmin ou dba, “como um código”. O Operador possui 3 componentes, um processo executor especializado ou orientado ao domínio – o Controlador – que fica no loop, observando uma aplicação ou uma infraestrutura, para garantir que seus estados durante a execução – o estado atual – são os desejados, e que estão documentados pelo estado declarado em uma linguagem específica do domínio.
Especificamente para o Kubernetes, temos uma descrição bastante concisa do Jimmy Zelinskie é que “Um operador é um controlador do Kubernetes que entende 2 domínios: Kubernetes e algo mais. Combinando o conhecimento de ambos os domínios pode automatizar tarefas que normalmente requerem um operador humano que entenda ambos os domínios”.
O diagrama abaixo explica esse estado de observabilidade do Operador para manter o estado desejado com base na comparação dos estados declarados e atuais.
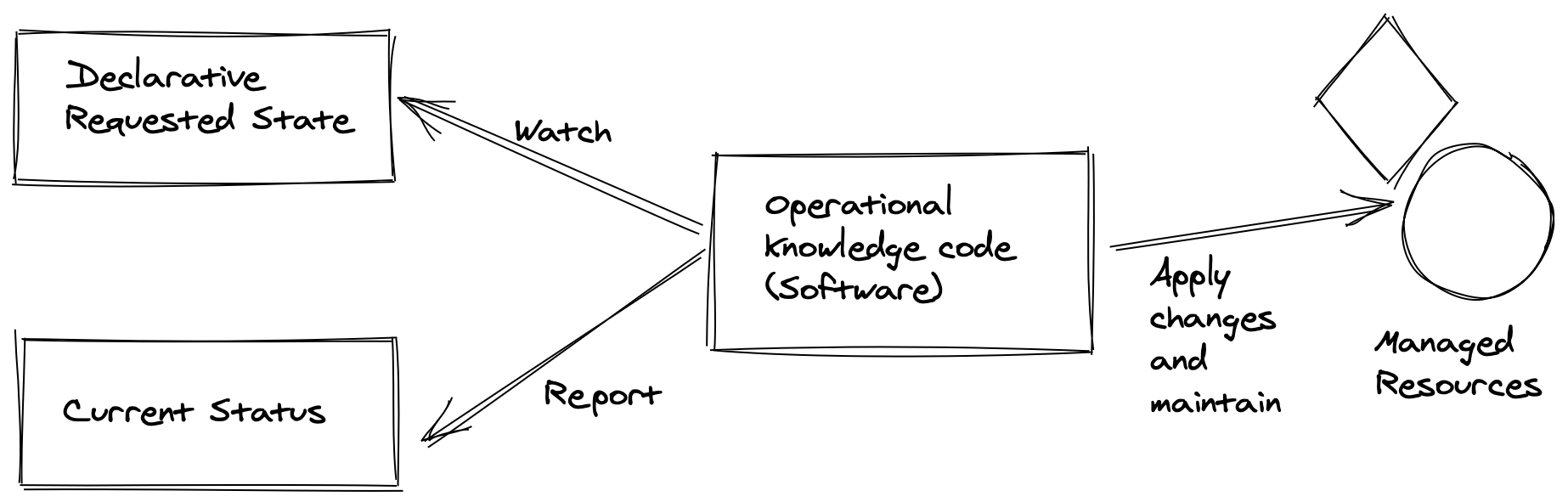
Assim, quando temos um aplicativo ou infraestrutura com estado para implantar e gerenciar, e decidimos construir um Operador, criamos um componente Controlador do Kubernetes com recursos para entender e interagir com o Domínio Kubernetes e suas APIs. E, ao mesmo tempo, entender esse domínio especializado e operar para fornecer gerenciamento com estado, automação de recurperação à falhas sem quebrar a consistência do aplicativo, também funções administrativas como backup/restauração, além de muitas outras tarefas operacionais cruciais, tudo “como código”.
Além do Controlador, o Operador também inclui Recursos Personalizados (em ingles “Custom Resources”) e Definições de Recursos Personalizados (CRDs - “Custom Resource Definitions”). O estado desejado da aplicação é encapsulado em um ou mais CRDs usando a linguagem específica do domínio, e o Controlador tem o conhecimento operacional para lidar com essas definições e leva os objetos da aplicação para o estado desejado.
Para obter mais detalhes sobre o Operador do Kubernetes, recomendo o CNCF Operator White Paper.
O Operador do Kubernetes do Oracle Database (a.k.a. OraOperator)
Não tenho medo de dizer que o Kubernetes é o orquestrador de infraestrutura da Cloud, fornecendo o mecanismo dinâmico para lidar com os Containers, fornecendo resiliência, autorrecuperação, uma espécie de elasticidade operacional. E executar e se aproveitar dessa tecnologia fantástica é a chave para o sucesso nas implantações nativas para a Cloud.
É fantástico que a Oracle tenha decidido tornar o Oracle Database nativo para Kubernetes, o que torna o Banco de Dados mais crítico e adotado do mundo, operável e observável por um bloco de construção essencial da infraestrutura nativa para a Cloud.
O Banco de Dados Oracle é uma infraestrutura com estado (“stateful”) e requer recursos operacionais em nivel empresarial, como backup/restauração, resiliência, automação de recuperação a falhas, etc. Então, para tornar viável executar o Oracle Database no Kubernetes, a Oracle disponibilizou o Operador de Kubernetes do Banco de Dados Oracle [ OraOperator ], que segue o padrão Operator. Criando a integração entre a infraestrutura do Kubernetes e a infraestrutura do Banco de Dados Oracle, permitindo que eles trabalhem juntos para entregar uma das mais poderosas plataformas de Gerenciamento de Dados Nativos para a Cloud.
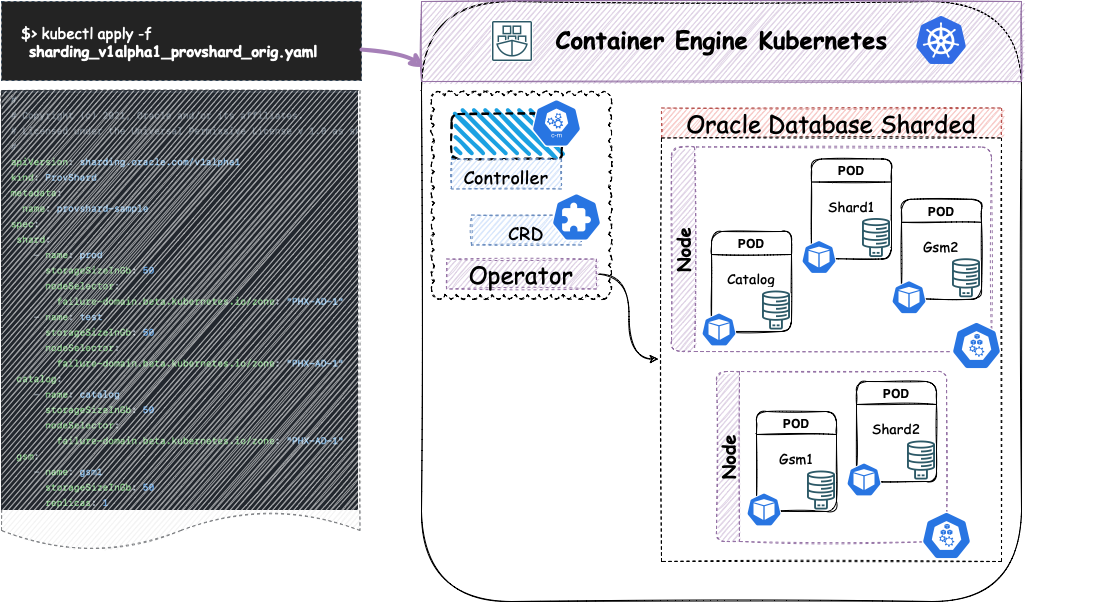
O projeto OraOperator implementou recursos do Kubernetes como Controladres e Definições de Recursos Personalizados para automatizar algumas tarefas do gerenciamento do ciclo de vida do Banco de Dados Oracle. Por exemplo, abaixo temos o código do CRD para Banco de Dados Sharding.
| |
Configurações suportadas pelo OraOperator
A versão atual (v0.1.0) também oferece suporte a tarefas de gerenciamento fora do cluster Kubernetes, o que ajuda os Database Reliable Engineers (DBRE) com seu trabalho diário, usando os comandos Kubernetes – kubectl –. Isso significa que é possível operar o Oracle Autonomous Database (ADB) usando o OraOperator.
A lista abaixo resume qual configuração do banco de dados Oracle e suas operações são suportadas:
- fora-cluster-K8s
- Configuração do Banco de Dados: Autonomous DB 1
- Operações:
aprovisionamento, vinculação, iniciar, parar, terminar (soft/hard), escalar (para cima/para baixo)
- Operações:
- Configuração do Banco de Dados: Autonomous DB 1
- no-cluster-K8s
- Configuração do Banco de Dados: Single Instance databases (SIDB) 2
- Operações:
aprovisionamento, copia, patch (no-local/fora), atualização dos parâmetros de inicialização do banco de dados, atualização das configurações do banco de dados (Flashback, Arquivamento), Oracle Enterprise Manager (EM) Express (um console basico de observabilidade)
- Operações:
- Configuração do Banco de Dados: Containerized Sharded databases (SHARDED)
- Operações:
aprovisionamento/implantação do banco de dados sharded e da topologia fragmentada, adicionar um novo fragmento, deletar um fragmento existente
- Operações:
- Configuração do Banco de Dados: Single Instance databases (SIDB) 2
Uma visão geral do Operador para Banco de Dados Fragmentado (Sharded)
Como exemplo de uso, o diagrama abaixo mostra a adoção do OraOperator para implantar a opção Banco de Dados Oracle Fragmentado (Sharded). Após instalar o Operator dentro do OKE 3, instalaremos nosso banco de dados fragmentado com dois contêineres para instâncias de DBs fragmentados, dois contêineres com GMS e uma instância do Catalogo.
Revisão da versão
A versão 0.1.0 vem com muitos recursos valiosos para nós desenvolvedores, e também para os BDREs. Ela funciona com o Banco de Dados Oracle de instância única (SIDB), e pode ser implantado em nosso laptop usando o Minikude, por exemplo. A próxima versão aumentará o número de distribuiç@oes de Kubernetes de outros fornecedores que estarão certificados, e também as opções de configuração de banco de dados, como bancos de dados locais (CDB/PDB).
Além disso, a versão atual do OraOperator (v0.1.0) deve ser utilizada apenas para desenvolvimento e teste. NÃO USE NA PRODUÇÃO.
Referências
Algumas referências para continuar o estudo:
- Oracle Database Operator for Kubernetes GitHub
- Material do meu amigo e também lider do projeto Kuassi Mensah (Diretor de Gerenciamento de Produto para acesso Java ao Oracle DB)
O que vem por aí?
Sim, este artigo é o piloto de uma série sobre o Operador de Kubernetes do Banco de Dados Oracle, e o próximo episódio será sobre “Introdução ao OraOperator para bancos de dados de instância única”.
Oracle Autonomous Database na Oracle Cloud Infrastructure (OCI) compartilhada, também conhecido como ADB-S ↩︎
Containerized Single Instance databases (SIDB) ↩︎
Oracle Container Engine for Kubernetes (OKE) é um serviço de Kubernetes gerenciado oferecido na Oracle Cloud Infrastructure. ↩︎